ChatGPT Retrieval Plugin 개발 (2) : 배포 및 실용 가이드
이번 글에서는 벡터 데이터베이스를 활용해 ChatGPT Retrieval Plugin의 개발과 배포를 어떻게 더 효율적으로 할 수 있는지에 대해 깊게 다룰 예정입니다. 환경 설정과 사전 준비는 이전 글에서 확인하실 수 있으니 참고해주시기 바랍니다.
ChatGPT Retrieval Plugin 개발 (1) : 아키텍처와 사전 준비
인공지능과 머신러닝의 빠른 발전에 따라, 개인이나 기업이 보유한 대량의 데이터를 효율적으로 활용하는 것이 중요해지고 있습니다. ChatGPT Retrieval Plugin은 개인이나 기업, 조직의 프라이빗 데
yunwoong.tistory.com
1. 벡터 데이터베이스란?
벡터 데이터베이스는 다양한 형태의 데이터를 벡터 형식으로 변환하여 저장하고, 빠르고 정확한 유사도 검색을 가능하게 하는 데이터베이스입니다. 이 글에서는 Pinecone을 예시로 들겠습니다. Pinecone은 API 호출만으로 쉽게 벡터 검색이 가능하며, 오픈 소스가 아니지만 무료 플랜을 제공하여 접근성이 좋습니다.
2. 라이브러리 설치 및 불러오기
pip install openai
pip install llama-index
pip install langchainfrom typing import Dict, List, Optional, Tuple
import openai
import pinecone
import pandas as pd
import numpy as np
import textwrap
from langchain.docstore.document import Document
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.chains import RetrievalQA
from langchain.vectorstores import Pinecone3. OpenAI 및 GPT 모델 환경 변수 설정
OPENAI_API_KEY = 'YOUR_OPENAI_API_KEY'
EMBEDDING_MODEL = "text-embedding-ada-002"
GPT_MODEL = "gpt-3.5-turbo"
openai.api_key = OPENAI_API_KEY4. Pinecone API 키 및 환경 설정
PINECONE_KEY = 'YOUR_PINECONE_KEY'
PINECONE_ENV = 'YOUR_PINECONE_ENV'
PINECONE_INDEX = 'YOUR_PINECONE_INDEX'
pinecone.init(api_key=PINECONE_KEY, environment=PINECONE_ENV)5. OpenAI와 Pinecone을 위한 사용자 정의 클래스 구현
class OpenAIEmbeddingsWrapper(OpenAIEmbeddings):
query_text_to_embedding: Dict[str, List[float]] = {}
document_text_to_embedding: Dict[str, List[float]] = {}
def embed_query(self, text: str) -> List[float]:
embedding = super().embed_query(text)
self.query_text_to_embedding[text] = embedding
return embedding
def embed_documents(self, texts: List[str], chunk_size: Optional[int] = 0) -> List[List[float]]:
embeddings = super().embed_documents(texts, chunk_size)
for text, embedding in zip(texts, embeddings):
self.document_text_to_embedding[text] = embedding
return embeddings
@property
def query_embedding_dataframe(self) -> pd.DataFrame:
return self._convert_text_to_embedding_map_to_dataframe(self.query_text_to_embedding)
@property
def document_embedding_dataframe(self) -> pd.DataFrame:
return self._convert_text_to_embedding_map_to_dataframe(self.document_text_to_embedding)
@staticmethod
def _convert_text_to_embedding_map_to_dataframe(
text_to_embedding: Dict[str, List[float]]
) -> pd.DataFrame:
texts, embeddings = map(list, zip(*text_to_embedding.items()))
embedding_arrays = [np.array(embedding) for embedding in embeddings]
return pd.DataFrame.from_dict(
{
"text": texts,
"text_vector": embedding_arrays,
}
)class PineconeWrapper(Pinecone):
query_text_to_document_score_tuples: Dict[str, List[Tuple[Document, float]]] = {}
def similarity_search_with_score(
self,
query: str,
k: int = 4,
filter: Optional[dict] = None,
namespace: Optional[str] = None,
) -> List[Tuple[Document, float]]:
document_score_tuples = super().similarity_search_with_score(
query=query,
k=k,
filter=filter,
namespace=namespace,
)
self.query_text_to_document_score_tuples[query] = document_score_tuples
return document_score_tuples
@property
def retrieval_dataframe(self) -> pd.DataFrame:
query_texts = []
document_texts = []
retrieval_ranks = []
scores = []
for query_text, document_score_tuples in self.query_text_to_document_score_tuples.items():
for retrieval_rank, (document, score) in enumerate(document_score_tuples):
query_texts.append(query_text)
document_texts.append(document.page_content)
retrieval_ranks.append(retrieval_rank)
scores.append(score)
return pd.DataFrame.from_dict(
{
"query_text": query_texts,
"document_text": document_texts,
"retrieval_rank": retrieval_ranks,
"score": scores,
}
)6. RetrievalQA 체인과 벡터 검색 환경 설정
num_retrieved_documents는 Retrieved Context의 수입니다.
num_retrieved_documents = 2
embeddings = OpenAIEmbeddingsWrapper(model=EMBEDDING_MODEL)
docsearch = PineconeWrapper.from_existing_index(
index_name=PINECONE_INDEX,
embedding=embeddings,
)
llm = ChatOpenAI(model_name=GPT_MODEL)
chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=docsearch.as_retriever(search_kwargs={"k": num_retrieved_documents}),
)7. 질문-응답 서비스 실행 및 결과 확인하기
query_text = "혹시 이동전화 업무 중 명변을 알아?"
response_text = chain.run(query_text)
retrievals_df = docsearch.retrieval_dataframe.tail(num_retrieved_documents)
contexts = retrievals_df["document_text"].to_list()
scores = retrievals_df["score"].to_list()
query_embedding = embeddings.query_embedding_dataframe["text_vector"].iloc[-1]
print("Response")
print("========")
print()
for line in textwrap.wrap(response_text.strip(), width=80):
print(line)
print()
for context_index, (context, score) in enumerate(zip(contexts, scores)):
print(f"Retrieved Context {context_index}")
print("===================")
print()
for line in textwrap.wrap(context.strip(), width=80):
print(line)
print()
print(f"score: {score}")
print()
print("Query Embedding")
print("===============")
print()
print(query_embedding)
print()
print(f"dimension: {len(query_embedding)}")Output :
Response
========
명변은 명의 변경을 의미합니다. 이동전화 업무 중에는 고객의 휴대폰 계약자나 사용자의 이름을 변경하는 것을 말합니다.
Retrieved Context 0
===================
이동전화 서비스 업무에서 명변은? 명변은 명의변경을 의미합니다. T끼리 온가족할인에 대해 알려주세요. T끼리 온가족할인은 SK텔레콤을 이용하는 가족의 휴대폰 회선을 결합하면, 결합한 회선의 합산
가입 연수에 따라 휴대폰 월정액을 할인받을 수 있는 결합상품으로, 이용요금은 무
score: 0.83498
Retrieved Context 1
===================
야? 서비스번호는 휴대폰번호를 말합니다. 김윤웅이 키우는 강아지는 골든리트리버 종으로 이름은 대군이입니다.
score: 0.832489431
Query Embedding
===============
[-6.12203740e-03 -3.59842373e-02 2.60245543e-02 ... -6.96773419e-03
1.68860372e-05 -7.25075660e-03]
dimension: 1536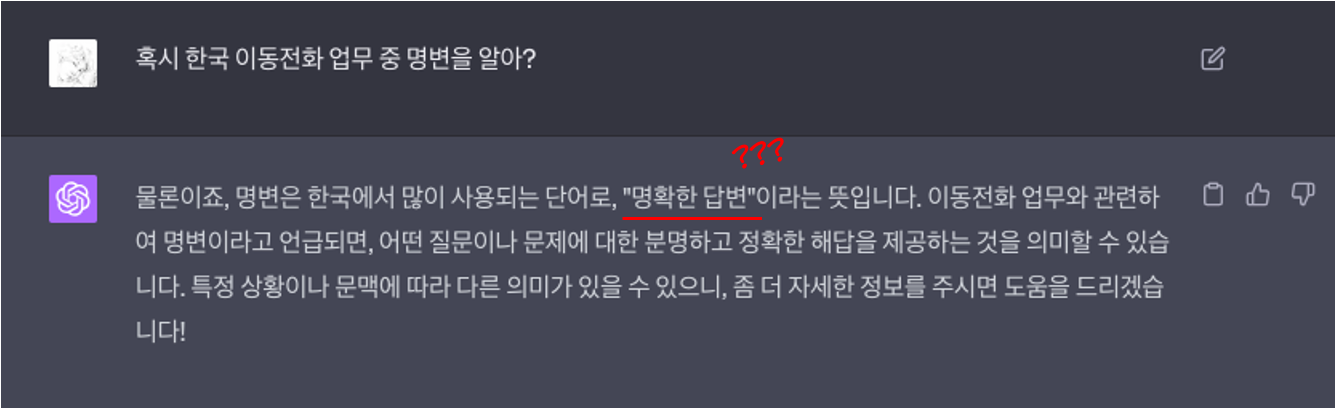
이번 글에서는 ChatGPT Retrieval Plugin을 활용한 질문-응답 서비스의 개발과 배포 과정을 자세히 살펴보았습니다.
ChatGPT는 일반적인 질문에는 잘 대응할 수 있지만, 특수한 비즈니스 용어나 업무 관련 질문에 대한 답변은 제한적일 수 있습니다. 예를 들어, "혹시 한국 이동전화 업무 중 명변을 알아?"라는 질문에 '명확한 답변'이라고만 답하였습니다.
그러나 ChatGPT Retrieval Plugin을 활용하면 개인이나 기업이 보유한 특화된 데이터베이스를 ChatGPT가 접근하여 해당 데이터에서 적절한 답변을 찾아 제공할 수 있습니다. 즉, 비즈니스 특화된 용어나 업무에 대한 세부적인 정보도 쉽게 알아낼 수 있게 되는 것입니다.
이를 통해 ChatGPT가 단순한 일반적인 질문뿐만 아니라, 특정 업무나 전문 분야에 대한 질문에도 더욱 정확하고 유용한 답변을 제공할 수 있게 되었으며 더욱 스마트하고 유용한 서비스를 제공할 수 있는 기회가 확장되었다고 생각합니다.
ChatGPT Retrieval Plugin 개발 (3) : 클라우드 배포
앞서 'ChatGPT Retrieval Plugin 개발 (1) : 아키텍처와 사전 준비'에서는 Retrieval Plugin의 기본 구조와 필요한 준비 과정에 대해 소개하고 'ChatGPT Retrieval Plugin 개발 (2) : 배포 및 실용 가이드'에서는 실제로
yunwoong.tistory.com
'Tech & Development > AI' 카테고리의 다른 글
| ChatGPT Retrieval Plugin 개발 (4) : ChatGPT에 개발한 Plugin 추가하기 (0) | 2023.09.23 |
|---|---|
| ChatGPT Retrieval Plugin 개발 (3) : 클라우드 배포 (0) | 2023.09.17 |
| Pinecone을 이용한 벡터 데이터베이스 시작하기 (0) | 2023.08.28 |
| ChatGPT Retrieval Plugin 개발 (1) : 아키텍처와 사전 준비 (0) | 2023.08.26 |
| StableCode 사용 가이드: AI 코딩 도구의 활용 방법 (0) | 2023.08.16 |