PandasAI: 데이터 분석을 위한 대화형 AI 도구
PandasAI는 Python 라이브러리로, 인기 있는 데이터 분석 및 조작 도구인 Pandas에 생성형 인공지능 기능을 추가합니다. Pandas와 함께 사용하도록 설계되었으며, 이를 대체하는 것이 아닙니다.

PandasAI는 대화형 인터페이스를 통해 Pandas를 사용하는 도구입니다. 이 도구를 통해 사용자는 데이터에 관한 질문을 하고, 이에 대한 답변을 Pandas DataFrame 형태로 받을 수 있습니다.
예를 들어, DataFrame 내의 특정 열의 값이 5를 초과하는 모든 행을 찾는 질문을 하면, PandasAI는 이 요구사항에 부합하는 행만을 담은 DataFrame을 반환합니다.
또한 PandasAI는 복잡한 질문에도 대응할 수 있으며, 요약 또는 데이터 분석 요청을 통해 그래프를 생성하는 것도 가능합니다. 이렇게 하면 사용자는 자신이 가진 데이터를 보다 깊이 있게 이해하고, 필요한 정보를 효과적으로 추출할 수 있습니다.
이와 같이 PandasAI는 대화형 쿼리를 통해 사용자가 복잡한 데이터 작업을 수행하게 해 주어, 데이터 처리와 분석 작업을 보다 간편하게 만들어줍니다.
1. 설치 (Installation)
PandasAI는 pip를 통해 설치할 수 있습니다.
pip install pandasai추가로 openai 패키지도 설치합니다.
pip install openai2. 사용법
OpenAI API 키 발급
먼저 OpenAI API를 사용하기 위해 API 키 발급이 필요합니다. 먼저 OpenAI API 사이트로 이동합니다. OpenAI 계정이 필요하며 계정이 없다면 계정 생성이 필요합니다. 간단히 Google이나 Microsoft 계정을 연동할 수 있습니다. 이미 계정이 있다면 로그인 후 진행하시면 됩니다.
OpenAI API
An API for accessing new AI models developed by OpenAI
platform.openai.com
로그인이 되었다면 우측 상단 Personal -> [ View API Keys ]를 클릭합니다.

[ + Create new secret key ]를 클릭하여 API Key를 생성합니다. API key generated 창이 활성화되면 Key를 반드시 복사하여 두시기 바랍니다. 창을 닫으면 다시 확인할 수 없습니다. (만약 복사하지 못했다면 다시 Create new secret key 버튼을 눌러 생성하면 되니 걱정하지 않으셔도 됩니다.)
Import packages
import pandas as pd
from pandasai import PandasAI
from pandasai.llm.openai import OpenAI
from pandasai.llm.open_assistant import OpenAssistantLoad CSV File
예제로 사용할 데이터는 kaggle 또는 데이터 분석에서 가장 많이 사용되는 타이타닉 데이터 파일이고 형식은 csv입니다.
- Survived : 생존 여부 (0 = 사망, 1 = 생존)
- Pclass : 티켓 클래스 (1 = 1등석, 2 = 2등석, 3 = 3등석)
- Sex : 성별
- Age : 나이
- SibSp : 함께 탑승한 자녀 / 배우자 의 수
- Parch : 함께 탑승한 부모님 / 아이들 의 수
- Ticket : 티켓 번호
- Fare : 탑승 요금
- Cabin : 수하물 번호
- Embarked : 선착장 (C = Cherbourg, Q = Queenstown, S = Southampton)
df = pd.read_csv("https://raw.githubusercontent.com/yunwoong7/toy_datasets/main/csv/titanic.csv")
df.head()
Usage
OPENAI_API_KEY는 자신의 OpenAI API Key를 입력합니다. (예: sk-xxxxxxxxxxxxxxxxxxxxx)
OPENAI_API_KEY = "YOUR OPENAI API KEY"현재 가능한 Model은 openai, open-assistant, starcoder 가 있습니다.
# OpenAI
llm = OpenAI(api_token=OPENAI_API_KEY)
# Starcoder
#llm = Starcoder(api_token="YOUR_HF_API_KEY")
pandas_ai = PandasAI(llm)그런 다음 제공된 대형 언어 모델로 Dataframe과 Prompt를 전달하여 실행합니다.
pandas_ai.run(df, prompt='What is the average age of passengers?')Output:
"On average, the passengers' age is around 30 years old."한국어로 질문을 할 수 있습니다.
pandas_ai.run(df, prompt='승객들의 평균 연령은?')Output:
"The average age of the passengers on the Titanic was 29.7 years old."다음으로 좀 더 복잡하게 객실 등급과 성별에 따른 생존자 수를 계산해 달라고 입력해 봤습니다.
pandas_ai.run(df, prompt='Calculate the number of survivors by room class and gender.')Output:
"There were a total of 91 female and 45 male survivors in first class, 70 female and 17 male survivors in second class, and 72 female and 47 male survivors in third class."타이타닉 데이터를 활용하여 생존 여부를 예측하는 모델을 만든다고 가정했을 때 가장 중요한 고려사항 중 하나는 어떤 특성(Column)이 모델의 예측 성능에 가장 큰 영향을 미치는지 파악하는 것입니다. 이를 위해 좀 더 복합적인 질문을 해보았습니다. 주어진 데이터를 이용하여 생존 여부를 예측하는 모델을 만들 예정인데 어떤 Column이 가장 중요하는지 물어봤습니다.
pandas_ai.run(df, prompt='We are trying to create a model that predicts the Survived column using data. Which column is the most important?')완벽히 만족스러운 답은 아니지만 나름 분석한 결과를 내놓습니다. 이렇게 중요도를 판단하게 되면 예측 모델을 만들 때 어떤 특성에 집중할지 결정할 수 있고 최종적으로 더 정확하고 효율적인 생존 여부 예측 모델을 만들 수 있을 것입니다.
Output :
"Based on the given data, we are trying to create a model that can predict whether a passenger survived or not. To determine which column is the most important for this prediction, we can look at the data types and missing values of each column. The columns include PassengerId, Survived, Pclass, Name, Sex, Age, SibSp, Parch, Ticket, Fare, Cabin, and Embarked. It seems that the Survived column is the most important one since it is the target variable we are trying to predict. However, we need to analyze the other columns to see if they have any significant impact on the survival rate. Additionally, we can see that the Age and Cabin columns have a lot of missing values, which may affect their usefulness in the model."PandasAI에 성별에 따른 생존율 그래프를 그려달라고 요청할 수 있습니다. PandasAI는 데이터 분석을 위해 다양한 형태의 그래프를 그릴 수 있는 기능을 제공합니다.
pandas_ai.run(df, prompt='Show the survival rate by sex in a graph')Output :
"Sure, I can create a graph that displays the survival rate based on gender."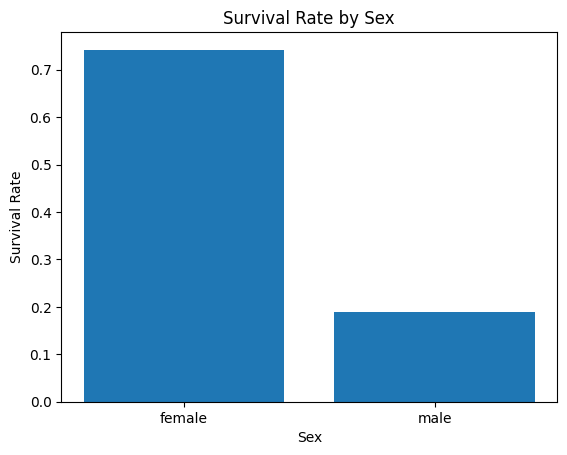
PandasAI를 사용하면 데이터를 쉽게 시각화하고, 데이터의 패턴을 쉽게 찾을 수 있다는 장점을 가지고 있습니다. 이는 데이터 분석가들이 보다 효과적으로 데이터를 이해하고 분석할 수 있도록 도움을 줍니다. 특히 Python과 Pandas를 주로 사용하는 분들에게는 PandasAI의 편리성이 큰 이점이 될 것입니다. Python과 Pandas는 이미 데이터 과학 분야에서 널리 사용되고 있으며, 이에 PandasAI의 적용은 데이터 처리 및 분석 프로세스를 더욱 강화하고 효율화할 수 있을 것입니다.
앞으로 PandasAI의 추가적인 업그레이드와 발전은 분석 작업을 더욱 용이하게 만들고, 더 복잡하고 깊이 있는 데이터 인사이트를 얻는데 도움을 줄 것입니다. 그로 인해 결국 데이터 분석가들의 업무 효율성을 높이고, 더 나은 의사결정을 가능하게 할 것입니다.
'Tech & Development > AI' 카테고리의 다른 글
| Meta AI 라마 2 (Llama 2): 사용 가이드 (0) | 2023.07.19 |
|---|---|
| 비정형 데이터 탐색: 벡터 임베딩과 벡터 데이터베이스의 이해 (0) | 2023.07.01 |
| [ Pynecone ] ChatGPT App 만들기 (Python) (0) | 2023.03.28 |
| [ Pynecone ] DALL·E 모델로 이미지를 생성 App 만들기 (Python) (0) | 2023.03.28 |
| [ Python ] 미디어파이프(Mediapipe)를 이용한 가상 마우스 (4) | 2023.01.31 |